
Хранение информации в виде самоопределяемых данных
Обычно информацию о типе хранимых в памяти данных мы узнаем из команд программы. Однако мы можем в ячейке памяти, где хранятся данные, указать и тип данных (целое, десятичное, символьное и т.д.), дополнив данные некоторым набором битов – тегом. Этот принцип организации памяти получил название теговой памяти. Наряду с типом данных в теге можно хранить и другие характеристики, например длину операнда, информацию об определении текущего значения переменной, использующего данную ячейку памяти, и т. д.
Что дает тег? Известно, что в IBM 370 имеется 15 различных команд ADD, формат одной из них требует двух 4?битовых полей для указания длины обоих операндов. Использование тегов позволило бы ограничиться одной командой, а тип подлежащих сложению операндов и их длину компьютер определял бы путем анализа содержимого тегов соответствующих операндов.
Расширив тег еще одним битом, мы могли бы использовать его в случае обращения к этой ячейке для незапрограммированного прерывания при возникновении определенной ситуации и переходе к процедуре ее обработки.
Бывают два типа тегов: статические, содержимое которых определяется перед выполнением программы и по ходу вычислений не изменяется, и динамическое – с наполнением его содержания во время вычислений и периодическим обновлением.
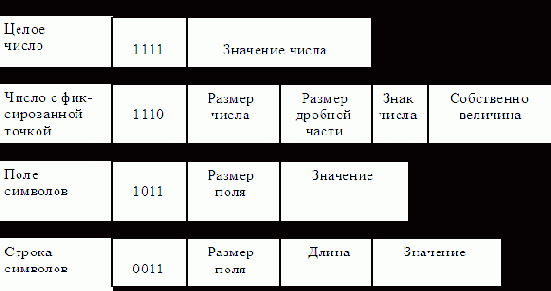 |
Вот пример типов структур элементов теговой памяти, ориентированный на языки программирования (рис. 1.6). Здесь стрелка "¯" разделяет тег и данные.
Рис. 1.6. Типы ячеек при теговой организации
Первые четыре бита определяют тип хранимой величины: целое, число с фиксированной точкой и т. д., затем идет количество цифр, длина и т. д.
Использование тегов позволяет найти некоторые ошибки. Например, может обнаружиться, что одним из операндов команды сложения является строка символов или число с плавающей точкой записывается в качестве адреса, или значение одного из операндов неизвестно и т. д. То есть идет защита типа данных.
Может возникнуть ситуация, когда складываем числа с фиксированной точкой, но позиции точки в числах разные, т. е.
необходимо предварительно выравнять эти позиции. Данные могут отличаться длиной или формой представления. Таким образом, возможно автоматическое преобразование данных.
Теги позволяют повысить скорость обработки команд. Это происходит, во-первых, из-за того, что обычно для преобразования данных надо генерировать компилятором отдельные наборы команд, а во?вторых, отпадает необходимость в извлечении из памяти и декодировании команд преобразования данных. Теги позволяют упростить алгоритмы некоторых операций. Так, для сравнения двух величин необходимо произвести их выравнивание (усечение до меньшей или дополнение до длинной), на что компилятор PL/1, например, генерирует код из 49 команд, а при теговой архитектуре потребуется одна машинная команда.
Структуры команд делаются более регулярными, за счет чего уменьшается разнообразие команд. Однако мы должны задаться вопросом, всегда ли уменьшение количества команд способно эквивалентно отразить исходное разнообразие операций. Всегда ли эквивалентна, например, операция арифметического сдвига и операция деления на 2?
Компилятор становится более простым и быстрым. Это следует из предыдущих рассуждений. Здесь не надо генерировать различный код в зависимости от типа данных, ибо набор команд инвариантен к типу обрабатываемых данных.
Теги позволяют сделать отладку более совершенной. В частности, дамп памяти становится более информативным.
Осуществляется независимость разрабатываемых программных средств от данных благодаря наличию команд, инвариантных к типу данных.
А что будет с объемом памяти для хранения программ и данных? Оказывается, хотя все данные требуют дополнительные поля, но за счет многократного и из многих команд обращения за данными, благодаря устранению избыточности информации в кодах операций команд в машинах с теговой организацией памяти потребуется меньший объем для хранения программ и данных, чем в ЭВМ с традиционной архитектурой. Проведенные эксперименты с программами на языке КОБОЛ показали, что если число обращений к операнду больше 3,5, то теговая организация уже выгодна и по объему памяти.
Среднее же число обращений к одному операнду в некоторых наборах экономических программ имеет коэффициент обращения > 10,4.
Эти рассуждения еще раз подтверждают мысль, что оптимальное решение при проектировании архитектуры машины можно принимать лишь при глубоком анализе ЯП и программ.
Экономия памяти происходит из-за ненадобности повторного генерирования кодов для функций контроля и преобразования данных. Экономии можно достичь и за счет того, что один тег можно заводить для всего массива данных и для всех элементов строки символов, так как последние содержат, как правило, одинаковые атрибуты.
Наряду с тегами, во многих машинах используются и дескрипторы. Это дополнительная информация, выполняющая роль косвенного адреса ячейки памяти с данными. В этих компьютерах команды содержат ссылки на дескрипторы, которые, в свою очередь, содержат ссылки на области памяти, хранящие значения операндов команд.
Основное отличие тегов и дескрипторов состоит в следующем: дескрипторы создают дополнительный уровень адресации, что требует увеличения затрат на формирование адреса, т. е. дескрипторы – это часть команды (программы), а теги – это часть данных.
Пример использования дескрипторов (рис. 1.7).
101 |
P |
I |
R |
W |
Длина |
Адрес |
Здесь первые три бита содержат тег. Если значение его 101, то данное слово дескриптор. Бит P указывает, находятся данные в основной памяти или во вспомогательной; I указывает, одиночный ли элемент описывает данный дескриптор или весь массив; R идентифицирует непрерывную или разрывную область памяти; W означает, что разрешено только чтение данных.